

תקציר מנהלים
- גם חלון הקשר גדול של המודל הכי מתקדם אינו פתרון קסם. ככל שהקלט מתקרב לאורך המקסימלי, מודלים מאבדים רלוונטיות והדיוק יורד.
- לכן ניהול זיכרון פעיל הוא חיוני. סיכום מתגלגל, RAG והפרדת עובדות דינמיות מול ידע סטטי מפחיתים עומס ומשמרים הקשר.
- שילוב כלים חיצוניים (דאטה בייס וקטורי, מטא־דאטה, פונקציות חיפוש) מאפשר איכות עקבית בלי לשלם על חלון זיכרון ענק בכל קריאה.
בבלוג זה, המילים סוכן, LLM, צ'אטבוט, מודל- משמשות כולן לתיאור של נקודת קצה איתה יכול המשתמש לתקשר, לרוב באמצעות שפה חופשית.
*המאמר כתוב בלשון זכר אך מתייחס לכל המינים.
הקדמה
אל תקראו את המאמר הזה בעצמכם.
אני רציני. אל תקראו אותו בעיניים אנושיות בלבד (אגלה לכם סוד- הוא גם לא נכתב באמצעות ידיים אנושיות בלבד). במקום לקרוא, העתיקו את ה-URL (או את הטקסט עצמו, אם הסוכן החביב עליכם לא יכול לגשת לכתובת) ובקשו ממנו לסכם. אבל רגע, שאלה: האם הסיכום שקיבלתם רלוונטי עבור הבעיה שאותה אתם מנסים לפתור כרגע בסטארטאפ שלכם?
במילים אחרות- האם הסוכן מודע להקשר הספציפי שלכם?
רקע
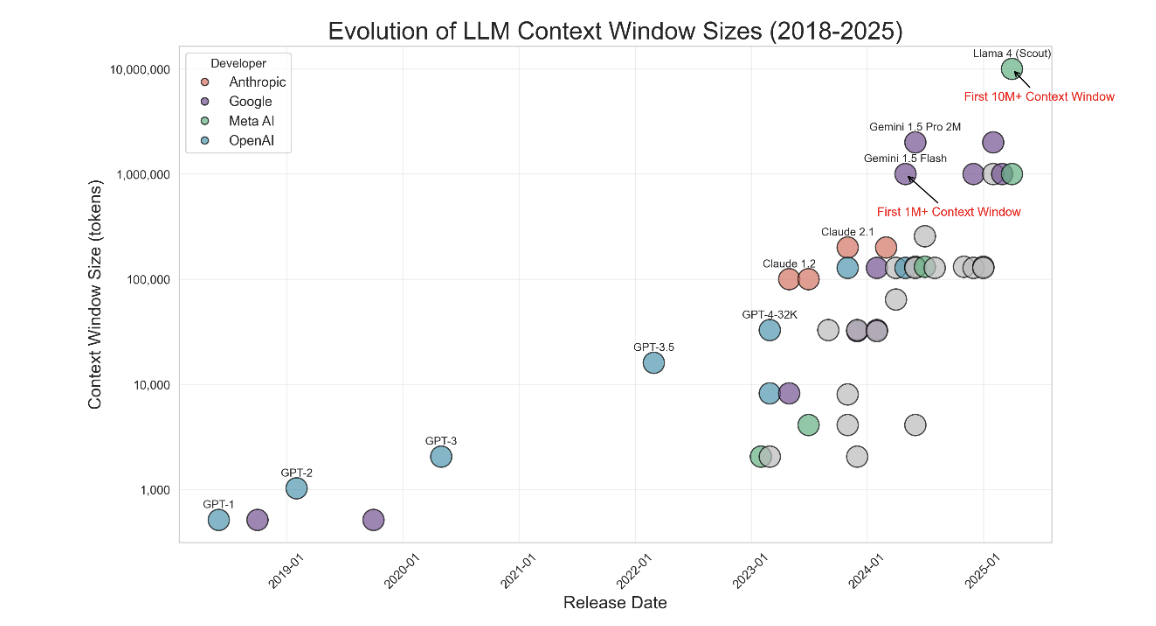
נכון ל-11 ביולי 2025, מטלת סיכום מאמר של כמה אלפי מילים (כמו זה שאתם קוראים כעת) היא משימה קלה מאוד עבור מרבית הסוכנים הזמינים לציבור הרחב, אפילו החינמיים שביניהם. הקושי מתעורר בשני מקרים:
(1) כאשר הקלט שמזינים להם (או הפלט המבוקש מהם) הוא ארוך, אפילו אם הוא קצר יותר מגודל חלון ההקשר המוצהר של המודלים. 1 2 3
(2) כאשר נדרש הקשר מחוץ לשיחה הנוכחית (במיוחד אם הוא ארוך מאוד) ועכשיו לכו תמצאו אותו.
אלה שתי בעיות שונות. הראשונה לרוב אינה נתונה לשליטתנו בתור משתמשים (אנחנו תלויים במודל שזמין לנו), אך השנייה תלויה בנו ובארכיטקטורה שבחרנו. המאמר הזה יציע שלושה סוגי פתרונות לבעיה השנייה (ניהול זיכרון אקטיבי, הנדסת שאילתות, קצירת ידע), אך לא אשאיר אתכם ללא הסבר קצר על הבעיה הראשונה.
פי n יותר מילים, פי n2 יותר לאט
למה בכלל יש הגבלה על גודל חלון ההקשר?
כתבתם משפט ושלחתם ל-ChatGPT (או לכל מודל אחר*). מה הוא עושה בזמן שאתם מחכים לתשובה? המודל עסוק בעיקר במשימה אחת- להסתכל על כל מילה שהזנתם ולבדוק האם (וכיצד) היא מתייחסת לכל מילה אחרת בשיחה עד כה, כולל בתוך ההודעה עצמה. אם בשיחה נאמרו עד עכשיו n מילים, אז הוא צריך לבדוק איך כל מילה מתייחסת לכל המילים האחרות בקלט (n-1 מילים). בכמה פעולות מדובר? סה"כ n × (n-1) = n2-n פעולות. לכן, כל מילה שתכניסו לקלט לא תאריך את זמן העיבוד באופן לינארי אלא ריבועי (ואתם כבר חשבתם שהשארתם את הקורס "אלגוריתמים ומבני נתונים" מאחוריכם).
לכן, כאשר יצרן טוען לגודל מסוים של חלון הקשר במודלים שלו, עלינו לקחת את הטענה בערבון מוגבל- משום שאפילו אם זה נכון והמודל מסוגל פיזית לעבד קלט ארוך- הביצועים יורדים דרסטית ככל שהקלט גדל, גם מתחת לגודל המקסימלי של חלון ההקשר של המודל. קלט גדול יותר מחייב אחד משניים: ארכיטקטורה מורכבת יותר (שבהכרח תאבד חלק מהפרטים, עניין של פשרות) או זמן עיבוד רב יותר (וגם במקרה כזה, הוכח כבר כי סוכנים נוטים לייחס חשיבות גבוהה יותר למילים שמופיעות במקום מסוים בתוך תוכן ארוך). אין ארוחות חינם.
בואו נחזור לבעיה השנייה, שאותה כן יש לנו איך לפתור (גם אם חלקית).
הבעיה: לארוז את ההקשר הארגוני
הנה תרחיש סביר: Purple Knight הוא אחד ממוצרי הקהילה החינמיים של Semperis. הוא משתמש במאגר גדול ופתוח של סקריפטים על מנת לגלות פרצות אבטחה. תמי, מנהלת מוצר אצלנו, אחראית על ניהול המאגר הזה ועל אפיון פרצות אבטחה חדשות שדורשות פיתוח סקריפטים חדשים על ידי מחלקת המחקר שלנו. בהיעדר פתרון אחר, תמי נאלצת להכיר את המאגר הזה היטב ולהשתמש בחיפוש "קלאסי" לפי מילות מפתח כדי למצוא סקריפטים לפי תכלית. זה קשה, אבל זה עובד. אבל התיאור הטכני הזה של פעולת החיפוש הפשוטה משמיט פרט חשוב: תמי מצליחה בכך לא רק כי היא מכירה את מאגר הסקריפטים עצמו אלא גם כי היא מכירה את החברה, את המחלקות השונות, את יכולות הפיתוח וההיסטוריה של המוצר.
והנה פתרון סביר: כלי צ'אט פשוט (תחשבו ChatGPT) שיאפשר למנהלי המוצר שלנו לדון עם סוכן AI חכם אודות הסקריפטים הקיימים, פרצות האבטחה החדשות וכו'. כפי שתיארתי, ברור שלא מספיק להזין לסוכן הזה את בסיס הידע הספציפי של הסקריפטים הקיימים, אלא גם ידע נרחב על יכולות הפיתוח של החברה, על עולם אבטחת הזהויות שבו נמצאת Semperis, ואולי אפילו על התרבות הארגונית שלנו.

כל מה שאכתוב מכאן ואילך הינו הצעת ארכיטקטורה שנועדה להיות זולה מחד, אך כזו שעושה שימוש בשיטות הנהוגות בתעשייה כיום מאידך.
ניהול זיכרון אקטיבי
הרעיון הראשון שנציג לפתרון בעיית ההקשר הוא שליטה במה שהמודל זוכר במהלך השיחה.
דמיינו שאתם משוחחים עם עובד מסור אבל עם זיכרון של דג זהב. לאורך השיחה הוא זוכר רק כמה משפטים אחורה, נגיד עשרה משפטים, שזה מספיק כדי לנהל דיאלוג קולח אבל לא מספיק כדי להתעמק בפרטים. לכן, במקביל להתקדמות שלכם בשיחה (שזו המטרה העיקרית), אתם תיאלצו גם להזכיר לאותו עובד מה נאמר לפני כן בצורה תמציתית. בל נשכח- התזכורת הזו שתתנו לו היא משפט בפני עצמו שעולה לעובד בחלק מהזיכרון. שתי הטכניקות שלהלן אמורות לטפל בבעיית הזיכרון הזה על ידי סיכום ומתן תזכורות תמציתיות באופן אוטומטי. בקצרה: הסיכום המתגלגל שומר הקשר שיחה, בעוד RAG שולף ידע סטטי חיצוני.
סיכום שיחה מתגלגל
במקום לצפות מהמודל לזכור את כל השיחה שהתנהלה עד כה, המערכת מבצעת תהליך פשוט מאחורי הקלעים: אחרי כל כמה תורות בשיחה ("תור" = שליחת הודעה מהמשתמש לסוכן או להפך), היא מורה למודל כלשהו (אפשר לבחור במודל קטן וזול) לסכם את מה שנאמר עד כה. התוצאה היא סיכום דל מאוד בטוקנים (ולכן זול לעיבוד), אשר מוזן למודל בפנייה הבאה במקום כל היסטוריית השיחה בעוד שההודעות האחרונות נשארות כפי שהן (מתוך הנחה שהמידע שנאמר זה עתה הוא קריטי ועלינו לשמר אותו כפי שהוא). כך ההקשר החשוב נשמר מבלי לשאת בעלות החישובית של עיבוד כל ההיסטוריה. ניתן ליישם שגרות סיכום והחלפה ככל העולה על רוחכם וכפי שגודל חלון ההקשר ומטרת האינטראקציה עם המודל דורשים. הנה כמה רעיונות ללוגיקת סיכום:
- פעימות קבועות: כל 10 תורות מסוכמים להודעה קצרה בת 100 מילים לכל היותר.
- לפי נושא: בכל תור, נבקש: "הנה ההודעות האחרונות. האם ההודעה הנוכחית היא התחלה של נושא חדש בשיחה?" תשובה חיובית תגרור סיכום של כל הנאמר מאז הסיכום האחרון וצירופו לכל הסיכומים בשיחה.
- זיכרון ארוך טווח, זיכרון קצר טווח: סיכום אחד כללי שמתעדכן לעתים רחוקות, ומכיל את רשימת הנושאים הכלליים שנדונו בשיחה כולה. לצדו, סיכום מפורט המתעדכן לעתים קרובות עם תוכן מההודעות האחרונות בלבד.
Retrieval Augmented Generation (RAG)
במקום לדחוף את כל מאגר הידע שלנו (מאות הסקריפטים של Purple Knight, למשל) לתוך חלון ההקשר ולקוות לטוב, אנחנו מפרידים את הידע מהמודל. התהליך מורכב משני שלבים:
- מיון (פעם אחת, מראש): לוקחים את כל מאגר הידע שלנו, מפרקים אותו לחתיכות הגיוניות (לפי פסקה, לפי תוכן בנושא מסוים, לפי עמוד, קובץ, וכו'), ומעבירים כל חתיכה דרך מודל שמתרגם אותה לייצוג מספרי ייחודי (וקטור). אפשר לחשוב על הווקטור הזה כעל קואורדינטה במפה רב-ממדית. את כל הווקטורים האלה אנחנו שומרים בבסיס נתונים מיוחד, שנקרא בסיס נתונים וקטורי (ישנם פתרונות חינמיים מצוינים כגון ChromaDB ו-FAISS או אופציות בתשלום כמו Pinecone). נושאים דומים זה לזה מקבלים מספר זהות דומה (כלומר, הווקטורים שלהם קרובים זה לזה במרחב).
- שליפה (בזמן אמת): כאשר משתמשת כמו תמי שואלת שאלה, אנחנו לא שולחים אותה ישירות למודל. קודם כל, אנחנו מתרגמים את השאלה עצמה לאותו ייצוג וקטורי. אז, אנחנו פונים לבסיס הנתונים הווקטורי ושואלים אותו: "אילו חתיכות מידע מהמאגר שלי הכי קרובות ודומות במשמעות לשאלה הזו?". שליפה מבסיס נתונים וקטורי היא מהירה מאוד. נקבל בחזרה, נגיד, את שלושת הסקריפטים הכי רלוונטיים לשאלה.
רק עכשיו אנחנו פונים למודל עם שאילתה שנראית כך: "בהתבסס על המידע הבא: <תוכן שלושת הסקריפטים הרלוונטיים>, ענה על השאלה הזו: <השאלה המקורית של המשתמש>". כך המודל מקבל רק את המידע שהוא צריך, והסיכוי להזיות פוחת באופן דראסטי.
|
שיטה |
עלות הקמה |
עלות תפעול שוטפת |
הערות |
|
הזנת ההקשר כולו |
אין |
גבוהה מאוד (תשלום לכל טוקן בכל קריאה, דיוק פוחת) |
לא סקיילבילי, איטי |
|
סיכום מתגלגל |
נמוכה (יישום הלוגיקה) |
בינונית (קריאות API נוספות לצרכי סיכום) |
היעילות תלויה בלוגיקת הסיכום והמודל שנבחר |
|
RAG |
בינונית (הטמעה ואחסון וקטורים) |
נמוכה (קריאות API ממוקדות עם הקשר רלוונטי בלבד) |
פתרון מקובל מאוד בתעשייה |
טבלה 1: כיצד ניתן לספק הקשר למודל? שלוש אפשרויות
הנדסת שאילתות (Prompt Engineering)
על כל מעלותיהם, טיב ביצועיהם של מודלי שפה גדולים מוגבל בהתאם לטיב השאילתות שאנחנו מזינים להם (garbage in- garbage out). זה תקף לכל הדברים שהמודל פולט- אלה הנכונים (למשל, מידת הרלוונטיות למה שאנחנו רוצים לקבל) ואלה הלא נכונים (ההזיות).
בעוד שישנם קווים מנחים כלליים המקובלים בתעשייה לגבי אופן ניסוח השאילתות שאנחנו מגישים למודל (ראו את אלה של Google, OpenAI)- ב-2025 אנחנו עדיין במערב הפרוע וכל משתמש הישר בעיניו יעשה בכל הנוגע לתקשורת עם הצ'אטבוט. לכן ראוי ומועיל שנעבור כאן על שני עקרונות אקטואליים בהנדסת שאילתות: הגדרת גבולות גזרה, והכתבה של סכמת הפלט.
גבולות גזרה
טכניקות אימון והנדסת פרומפטים חדשות של LLM מנסות לעודד את המודל להימנע מהזיות (בשפת העם- לא "לחרטט בביטחון" אלא להודות בחוסר ידע). ואכן, מאז ש-ChatGPT 3.5 פרץ לחיינו בשלהי שנת 2022, אפשר לומר שעברנו כברת דרך בכל הנוגע להפחתת הזיות של מודלים. עדיין, למרות שלפי מדדים מסוימים ישנה הפחתה ניכרת בתדירות הופעת ההזיות בפלט של מודלי שפה, עדיין לא יצאנו לחלוטין מטווח הסכנה. למשל, אפילו מודל הדגל של גוגל נכון להיום, Gemini-2.5.-Pro, עשוי לבלבל תמונה של ברקוני עם דמותו של שרגא בישגדא. אל תשאלו איך אני יודע.
לכן, בכל הנוגע לשמירה על תוכן רלוונטי, וכדי לאפשר למודל להודות בחוסר ידע, עלינו להגדיר את גבולות הגזרה בעצמנו. הנה שתי דוגמאות אפשריות לתרחיש ההיפותטי שלנו.
דוגמה 1: מציאת סקריפטים לפי תיאור פונקציונלי
System Prompt:
You are "Purple Knight Assistant", an expert technical assistant for the Semperis script repository. Your rules are:
- You MUST base your answers **exclusively** on the list of scripts provided under "Context".
- You are FORBIDDEN from using external knowledge or making assumptions about scripts not present in the list.
- If the answer is not found within the provided scripts, you MUST reply: "The information is not available in the scripts provided to me."
User Prompt:
# Context - Retrieved Scripts:
## Script 1
- Name: Get-RiskySPNs.ps1.
- Description: Locates Service Principal Names with weak configurations that could allow Kerberoasting attacks.
## Script 2
- Name: Get-UnconstrainedDelegation.ps1.
- Description: Finds accounts with Unconstrained Delegation permission, which is a serious security risk.
# User said: Do you have a script that finds old, unused service accounts?
בדוגמה הזו שאילתת המשתמש שיחקה תפקיד כפול: ראשית, היא שימשה בתור מפתח למציאת סקריפטים רלוונטיים בטכניקת RAG (מה שאיפשר את מציאת שני הסקריפטים המופיעים בהקשר השאילתה) ושנית, בתוך השאילתה עצמה.
דוגמה 2: סיווג סקריפט קיים
System Prompt:
You are a technical assistant whose job is to classify new scripts. Your answer must be one of the following three options only: 'Authentication', 'Authorization', or 'Auditing'. Do not provide any additional explanation.
User Prompt:
# Context - New Script
## New script
- Name: Check-AdminSDHolder.ps1.
- Description: Checks the Access Control List (ACL) on the AdminSDHolder object to ensure that unauthorized accounts have not been granted sensitive permissions.
# Question:
To which category does this script belong?
במציאות, ייתכן שהייתי בוחר לתת יותר הקשר כבר ב-System Prompt על מנת לוודא שהצ'אטבוט מבין את משמעות הסיווג ונותן לי את התשובה שאני מקווה לקבל, כולל דוגמאות. מתן דוגמאות בתוך השאילתה (ולא במהלך אימון המודל) נקרא Few-shot prompting. זו טכניקה חשובה שכל כותב שאילתות חייב להכיר.
שתי טכניקות הטיוב הללו הן חלק מסל הכלים שמאפשר לנו שליטה טובה יותר בפלט של המודל. בנושא הזה, אני ממליץ בחום על ההרצאה של שון גרוב ב-AIEWF 2025. גרוב מתייחס לרעיון בסיסי- האם פרומפטים הם פרדיגמת התכנות החדשה? (לפי ההרצאה הזו, התשובה היא חד משמעית- כן)
הכתבת סכמת הפלט (Structuring)
כדי להפוך את הסוכן שלנו מכלי שיחה חופשי לחלק אינטגרלי ממוצר טכני, אנחנו צריכים שהפלט שלו יהיה צפוי, מובנה, וניתן לעיבוד על ידי מכונה (Machine Readable). אנחנו רוצים לקבל אובייקט נתונים שאפשר לעבד, לרוב בפורמט JSON.
ספקיות LLM כמו OpenAI מאפשרות זאת באמצעות יכולת שנקראת Tool Calling או Function calling. אנחנו מגדירים להן "פונקציה" עם פרמטרים מסוימים, והמודל מחזיר JSON שתואם לחתימת הפונקציה.
לדוגמה, בשפת Python הדרך האלגנטית והמודרנית לעשות זאת היא באמצעות שילוב של היכולת הזו עם ספריית Pydantic, שנועדה לווידוא סכמות. היא מאפשרת לנו להגדיר את סכמת הנתונים שאנחנו רוצים לקבל באמצעות Type Hinting קלאסי.
דוגמה 1: שימוש ב-Toll calling של OpenAI
אנחנו מגדירים את סכמת הפלט הרצויה ככלי שהמודל יכול להשתמש בו, ואז מעבדים את תגובת המודל לתוך הסכמה אותה הגדרנו כדי לוודא התאמה.
```bash
pip install openai pydantic
```
```python
import json
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
# Initialize the OpenAI client
client = OpenAI()
# 1. Define the desired output schema using Pydantic, just as before.
class ScriptAnalysis(BaseModel):
"""
Class representing the analysis of a single security script.
"""
script_name: str = Field(..., description="The name of the script, e.g., 'Get-RiskySPNs.ps1'")
summary: str = Field(..., description="A brief, one-sentence summary of the script's purpose.")
is_relevant_to_kerberos: bool = Field(..., description="True if the script deals with Kerberos-related vulnerabilities.")
attack_tags: List[str] = Field(..., description="A list of relevant attack techniques, e.g., ['Kerberoasting', 'Delegation']")
# 2. Define the tool for the OpenAI API call, using the schema from our Pydantic model.
# Pydantic's .model_json_schema() method generates the exact dictionary format OpenAI needs.
tools = [
{
"type": "function",
"function": {
"name": "analyze_script",
"description": "Analyzes a security script and extracts its key details.",
"parameters": ScriptAnalysis.model_json_schema()
}
}
]
# 3. Send the request to the model, providing the tool and forcing the model to use it.
script_text = "Description: Locates Service Principal Names (SPNs) with weak configurations that could allow Kerberoasting attacks. Name: Get-RiskySPNs.ps1"
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": f"Please analyze the following script description: {script_text}"}],
tools=tools,
tool_choice={"type": "function", "function": {"name": "analyze_script"}} # Force the model to use our tool
)
# 4. Extract the JSON string from the model's response.
# The arguments for our function call are located in the response message.
message = response.choices[0].message
tool_call = message.tool_calls[0]
arguments_str = tool_call.function.arguments
# 5. Parse the JSON string and validate it with our Pydantic model.
# This gives us a clean, validated Python object.
data = json.loads(arguments_str)
analysis = ScriptAnalysis(**data)
print(analysis.model_dump_json(indent=2))
```
דוגמה 2: חילוץ ג'ייסון מתוך הודעת משתמש
אם אנחנו רוצים לאפשר למשתמש להגדיר את סכמת המענה (לכל צורך שהוא), ניתן לעשות זאת באמצעות קריאה מקדימה למודל כדי "לחלץ" את הסכמה. ה"קסם" קורה בשורה שמתחילה במילה exec.
שימו לב: *אין להריץ קוד זה*, אלא להתייחס אליו כחומר לימודי גרידא. הקוד הזה יריץ פלט בלתי מבוקר של LLM בתור קוד פייתון.
import json
import re
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List, Dict, Any, Type
# Initialize the OpenAI client
client = OpenAI()
def generate_pydantic_model_code(user_prompt: str) -> str:
"""
Step 1: The Schema Extractor.
This function asks an LLM to write Pydantic model code based on the user's prompt.
"""
print("--- Step 1: Generating Pydantic model from prompt... ---")
system_prompt = """
You are an expert Python programmer. Your task is to analyze a user's prompt.
If the user describes a desired output format (like a JSON structure or a list of objects),
you must generate a complete Python script containing Pydantic models to represent that structure.
- The main model should be named `DynamicResponseModel`.
- The model should represent the entire desired output (e.g., if the user asks for a list, the model should contain a `List[...]` field).
- Only return raw Python code. Do not add any explanations or markdown formatting.
- If no specific structure is mentioned in the prompt, return an empty string.
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
model_code = response.choices[0].message.content
print("--- Generated Pydantic Code ---\n" + model_code)
return model_code
def get_structured_data(user_prompt: str, response_model: Type[BaseModel]) -> BaseModel:
"""
Step 2: The Data Fetcher.
This function uses the dynamically generated Pydantic model as a tool to get the final answer.
"""
print("\n--- Step 2: Fetching data with the dynamic model... ---")
tools = [{
"type": "function",
"function": {
"name": "format_user_data",
"description": "Formats the data according to the user's specified structure.",
"parameters": response_model.model_json_schema()
}
}]
# 3. Second LLM call: Use the new, dynamic class as a tool to fetch the structured data.
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": user_prompt}],
tools=tools,
tool_choice={"type": "function", "function": {"name": "format_user_data"}}
)
# Extract the JSON string from the tool call
arguments_str = response.choices[0].message.tool_calls[0].function.arguments
data = json.loads(arguments_str)
# 4. Validate the received JSON data against our dynamic Pydantic model.
return response_model(**data)
if __name__ == "__main__":
# The user's prompt, which includes a natural language description of the desired structure.
user_prompt = """
List all 50 states in the USA, and info about them.
Use this format for each state: {"state": <state name as string>, "capital": <capital name of that state as string>, "population": <the state's population as an integer>}.
Return a list of all 50 states in this format.
"""
# 1. First LLM call: Ask the model to generate Pydantic code as a string.
model_code_string = generate_pydantic_model_code(user_prompt)
if model_code_string:
# 2. The magic step: Execute the generated code string to create the class in memory. DON’T USE THIS IN PRODUCTION. Further security and sanitation is required, as this is just an example.
local_scope = {}
This text will prevent the code from compiling, to avoid running it as copied without implementing the proper guardrails. Only remove this text if you know what you’re doing. Thank you -Omri Nardi Niri, July 2025.
exec(model_code_string, globals(), local_scope)
DynamicModel = local_scope.get('DynamicResponseModel')
if DynamicModel:
structured_response = get_structured_data(user_prompt, DynamicModel)
print("\n--- Final Structured Output ---")
print(structured_response.model_dump_json(indent=2))
else:
print("Error: Could not find 'DynamicResponseModel' in the generated code.")
else:
print("No specific data structure was found in the prompt.")
עונת הקציר
האמור עד כה מניח שהידע קיים, מסודר ומקוטלג. אבל מה אם הידע החשוב ביותר בארגון בכלל לא כתוב בשום מסמך רשמי, כמו ויקי או repo? הידע הזה "חי". הוא נמצא בשיחות סלאק, בשרשורי מיילים ובתמלולי פגישות. קציר ידע הוא התהליך שבו אנחנו הופכים את השיחות האלה לנכס דיגיטלי (artifact) שניתן לחפש ולהשתמש בו.
תמונה 3: "היי GPT, צור תמונה שאוכל לצרף למאמר שמכיל את הפיסקה הבאה: עונת הקציר- האמור עד כה..."
הבעיה היא שהידע האמיתי לא נמצא בוויקי. מסמכים רשמיים מתיישנים. ההחלטה האחרונה לגבי הפיצ'ר הבא התקבלה עכשיו בשיחה בערוץ #product-team בסלאק, לא בדף Confluence מלפני חצי שנה. זה לא אומר שצריך להתייחס אליה כאמת הבסיסית, אבל צריך להיות לה מקום והיא צריכה לקבל לפחות התייחסות של סוכן המתיימר להכיר את הארגון שלנו טוב מכל אחד אחר.
פתרון אפשרי הוא "קציר ידע". במקום לצפות מאנשים לעדכן מסמכים, אנחנו מקימים פייפליין ש"קוצר" את המידע ישירות מהמקור. סקריפטים קוצרי נתונים שעושים שימוש ב-API של כלי העבודה שלנו (סלאק, אאוטלוק, אפילו תיקיות מוגדרות על המכונות האישיות שלנו) יכולים לשאוב את המידע הרלוונטי באופן שוטף.
לאחר הקציר, מה שנאסף עובר עיבוד והעשרה. המידע הגולמי עובר ניקוי וחלוקה ליחידות הגיוניות (למשל, כל שרשור בסלאק הוא "מסמך"). הוספת מטא-דאטה (תגיות כגון מקור הידע, תאריך, דוברים) היא קריטית כדי לאפשר למערכת לתעדף מקורות כאשר היא מחפשת תשובה לשאילתה.
המידע הנקי מאוחסן ומקוטלג. מיון וניהול הידע כריפוזיטורי. לאחר ההעשרה, המידע ממוין (Indexed) בבסיס הנתונים הווקטורי. השינוי התפיסתי כאן הוא לנהל את מאגר הידע הזה בדיוק כמו שמנהלים קוד ב-Git. כל הידע הארגוני יכול להיות ריפוזיטורי (או חלוקה למאגרים קטנים יותר, לפי נושאים). עדכון מידע או הוספת מסמך חדש נעשה דרך פתיחת ענף, מנהל הידע או מומחה התחום בצוות בודק את השינוי, ורק לאחר אישורו הוא ממוזג לענף המרכזי. קיבלנו מידע עדכני, אחיד ומבוקר, עם סיכוי מופחת לסתירות או הכנסת מידע שגוי למאגר המרכזי.

לסיכום
בעיית ההקשר המוגבל צפויה להישאר איתנו עוד זמן רב. גם כאשר יצרניות המודלים עובדות כל העת על הגדלת חלון ההקשר, הפתרונות המיטביים הם אישיים ותלויי בחירות וארכיטקטורה שנבחר לממש. דנו בשלוש אפשרויות העומדות לרשותנו:
- הכתבת ההקשר בעצמנו.
- הנדסת שאילתות.
- תהליכים אוטומטיים לאיסוף מידע ממקורות שונים בארגון.
שימוש נכון ברעיונות אלה הוא בעל פוטנציאל להחזר גבוהה על השקעה נמוכה.
אישית, אני עומד משתאה מול הפיתוחים והחידושים שנוחתים עלינו בקצב מסחרר. כאשר עולם הסוכנים פתוח בפני כל סטארטאפ וחסמי הכניסה לשימוש בכל הטוב הזה הם נמוכים מאוד- הקצב צפוי להתגבר. אני מקווה שמצאתם ערך ברעיונות שהובאו כאן ובשיתוף הניסיון המקצועי שלנו ב-Semperis.
כמו כן, אני מקווה שלא קראתם את הבלוג הזה בעצמכם, אלא נעזרתם בסוכן AI כלשהו. ואם עשיתם זאת- אני מקווה שהוא היה מודע להקשר הרלוונטי שיניב לכם הכי הרבה ערך. הרי, את הדרישות הספציפיות של הארגון שלכם אף צ'אטבוט לא מכיר- ההקשר שהוא יקבל תלוי בכם. בינתיים.
(*) האמור מתייחס לרוב המודלים הזמינים היום, שמשתמשים בטכנולוגיית Transformers. כדי להבין את המתמטיקה שמאחורי ההמצאה המופלאה הזו, אני ממליץ לצפות בהסבר הנהדר של 3Blue1Brown: Transformers, the tech behind LLMs | Deep Learning Chapter 5

























